

How To Optimize FileMaker Unstored Calculation Functions
There’s always room for improvement and that certainly applies to custom app development. We’ve discussed some of the things to watch out for when designing our custom FileMaker apps, such as how to deploy them efficiently when we access FileMaker remotely and improve the performance of record creation and modification. Mitigating these bottlenecks alone can transform our trusty old commuter cars into the hot rods we’ve always dreamed of. But even the best-oiled machines might need some internal reengineering from time to time to continue humming down the road.
More often than not, when we as problem solvers start on our journey to create the killer app that will improve our workflows and solve our complex work ruts, we tend to focus on the bare minimum to get the app to work. We prioritize function over form at that point, but eventually, we’ll circle back to optimize how the app handles its tasks. Take, for instance, an inventory tracking system, a primary function probably requires the following simple calculation:
Inventory Received − Inventory Shipped = Inventory In Stock.
But that simple calculation often ends up becoming more complex:
(Inventory On Order − Inventory Received) − Inventory Sold, Not Shipped = Inventory Available To Sell.
The complexity of this calculation will likely increase as folks want granular details about the numbers. This natural slide toward complexity, coupled with the sheer quantity of transactions we track, will continually build over time and conspire to slow everything down. How do we put the pep back in the old jalopy without sacrificing accuracy? Well, often, the answer is to replace the live – unstored, in FileMaker parlance – calculations with something else.
WHAT ARE UNSTORED CALCULATIONS?
Before we talk about optimizing unstored calculations in FileMaker, let’s first discuss what unstored calculations are and how they work. An unstored calculation field is merely a calculation that has been manually marked as unstored. FileMaker will automatically flag a calculation as unstored if it has certain dependencies (parts of the calculation, such as fields and variables) from a separate table or another unstored calculation. We can tell if our calculations are unstored by looking in the field list.

We can also view the field’s options card.
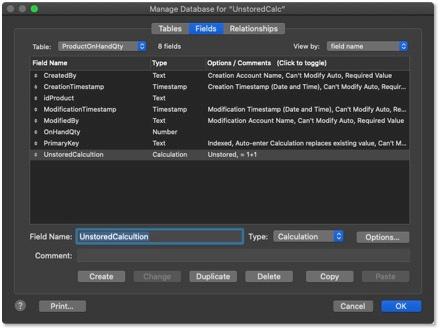
FileMaker designates certain fields as unstored because it would take a long time for the system to continually check and store the results of these calculations every time something changes somewhere in the solution. So, FileMaker only recalculates these fields when they’re displayed to the user. This is great for users who aren’t using that particular data at the time, but it’s a different experience for users who are using it. Going back to our inventory example, the users who are currently looking at the Inventory Dashboard, entering an order or trying to find out if the stuff they want is on hand would be impacted by the calculations. And for those select few viewing these aspects of the app, the lag can be utterly frustrating.
SOMETHING ELSE IN STORE
Application development is an iterative process. Of course, our workflows evolve, but we might also find ways to do things more efficiently within our apps later on than when we were under a tight deadline to complete a task or turn-around a report. User feedback might also motivate us to improve a process and/or calculation eventually.
In and of themselves, there’s nothing wrong with unstored calculations. They’re lightweight and typically don’t slow anything down. In fact, in some cases, they’re necessary for some things to work correctly or are the only option for other functions like hide conditions and conditional formatting. Nonetheless, within fields, we often have other options if we need them. So if we do run into a situation where our users mention that screens take an inordinately long time to redraw or lists are sluggish while scrolling, chances are the culprit is some complex unstored calculation either in a field or hiding in some layout element like a hide condition or conditional format.
How do we solve this performance issue, especially when we know that an unstored calculation is designed to be a performance enhancement, to begin with? The answer is to capture the change at the source. It would make sense to perform the function when we need it. Most unstored calculations track things that change irregularly like inventory levels, unpaid invoice totals and project progress. A change generally occurs when a person or process modifies or creates some piece of data, like when we mark a task complete or receive ordered items or a payment from a customer. Most of these things can be captured at the time of the event and passed on to another place further up the information ladder.
Let’s flesh this out a little more. For example, we receive an item in our warehouse and we want to increment our inventory quantity on hand accordingly. We can accomplish this in a few different ways, including simply entering the data into a field. But, we could also create a scripted process that would capture the amount received and then behind the scenes increment the on-hand quantity by the corresponding amount – receive 2, add 2. We would set up similar processes at all the points in our system where folks can indirectly modify the on-hand quantity, such as shipping, invoicing and processing returns. We could also set up script triggers on each of these fields to do this or even schedule a script that would run hourly on our server to manage the workflow. The bottom line is that we’ve transformed the on-hand quantity field from a complex, continually churning calculation into a static number field. This static number field is super fast to find on, sort by and display in a list, unlike the unstored calculation it replaces.
There’s one thing to look out for when we utilize this incrementing approach, especially if we’re in a multi-user environment, and that is record locking. Because we’re directly modifying a record, we could run into a situation where another user is manually editing a field of the master record we’re trying to increment. They might be trying to change the item name, for example. In this case, our attempt to increment the on-hand quantity would be ignored because the other user has locked the record. Consequently, our inventory numbers would be off. One way around this is to move the on-hand quantity field to a separate table and relate it to the Product table (a one-to-one relationship).
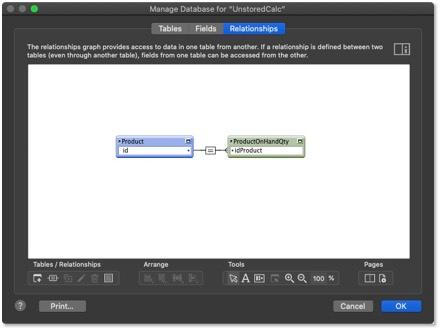
This allows us to increment the available quantity without worrying about someone else locking the product record. To make this even more foolproof, we typically place a loop in the increment script that checks to see if the record is locked and if it is, the script will wait a moment before trying again.
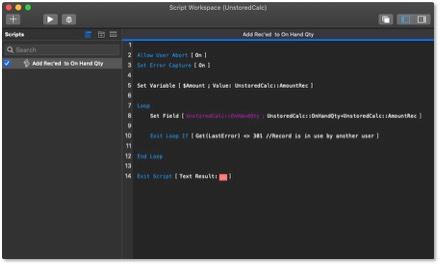
Because the only operations that are trying to modify this record are scripts, the delay we might experience should be very brief.
STORE UP PERFORMANCE
These are only a few of the ways we can restore performance from our unstored calculations. Remember, unstored calculations are helpful and in fact, they’re often easier to set up and maintain than a scripted incrementing process. We only suggest finding an alternative if they’re causing performance issues. There’s no reason to put a v12 supercharged engine into a minivan when its purpose is to maneuver through populated areas carefully. But if our jobs demand that minivan to scream across the desert, perhaps an engine swap and a monster truck suspension are in order!
And that wraps up our three-part discussion on FileMaker performance tactics. We hope you found our suggestions helpful and productive. Check out some of our other FileMaker development tips and tricks.